-

-
-

-
-

-
-

- 010-56548231
-

![]()

![]()

![]()

![]()
![]()
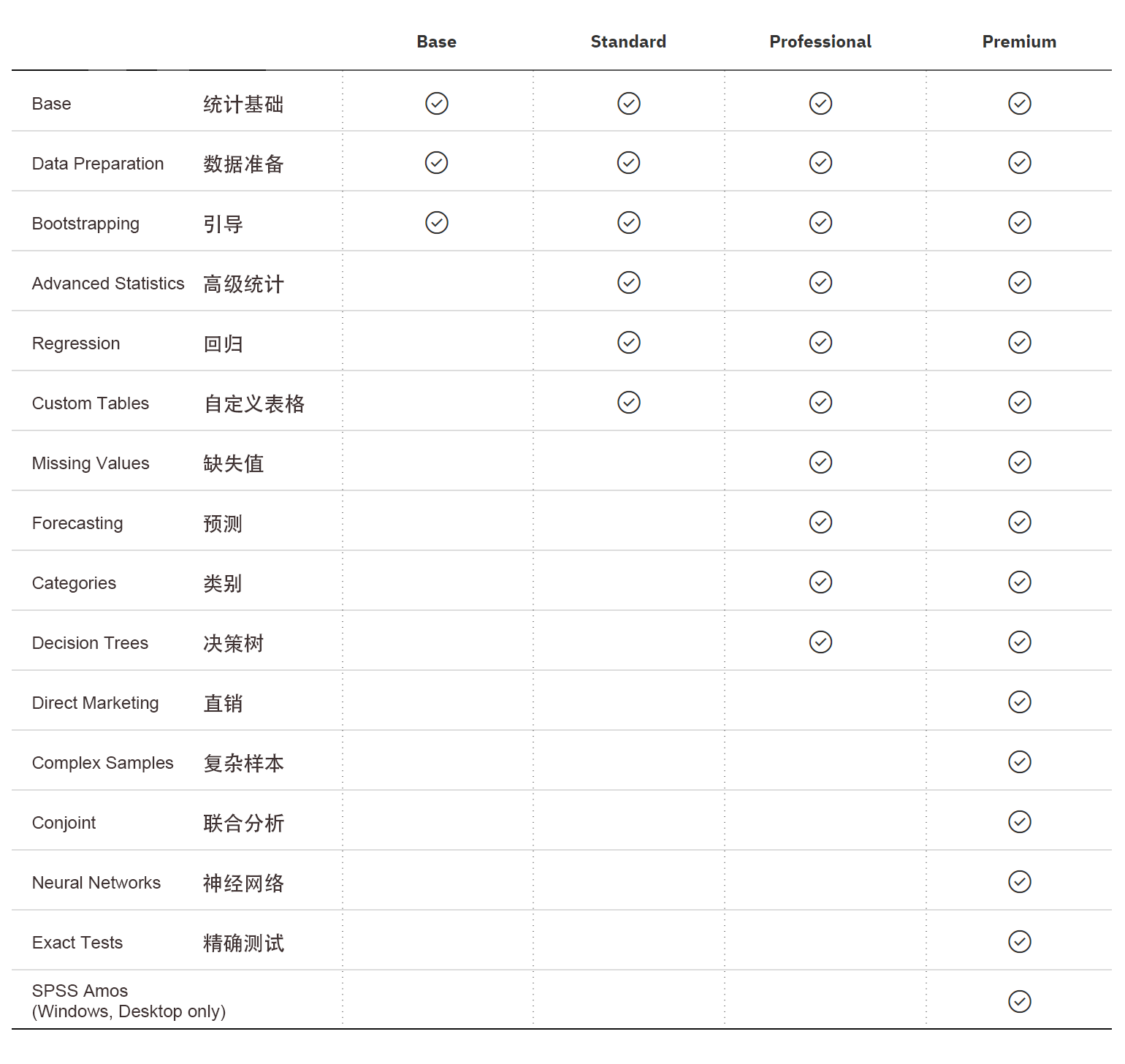
 IBM SPSS Statistics 32—大数据分析软件
IBM SPSS Statistics 32—大数据分析软件
IBM SPSS Statistics Premium Edition 集所有功能于一身的版本,专为有多种高级分析需求的科研人员和大型企业而设计。
IBM SPSS Statistics Premium Edition 帮助数据分析人员、规划人员、预测人员、调查研究人员、程序评估人员及数据库营销人员等在分析过程的每个阶段轻松地完成任务。它完全集成了 Statistics 功能,以及用于整个企业/科研项目内各种专门的分析任务的相关产品。该软件能够显著提高生产力,有助于特定项目和业务目标取得出色成果。
IBM SPSS Statistics Premium Edition 包括以下功能:
一、线性模型
提供各种回归和高级统计程序,旨在适应描述复杂关系的数据的固有特征。
• Statistics Premium 包含广义线性混合模型 (GLMM),用于分层数据。
• 该软件具有通用线性模型 (GLM) 和混合模型程序。
• 它包含广义线性模型 (GENLIN),包括广泛使用的统计模型,例如针对正态分布响应的线性回归、针对二元数据的逻辑模型,以及针对计数数据的对数线性模型。GENLIN 还通过其非常通用的模型公式提供众多实用的统计模型。
• 广义估计方程 (GEE) 程序扩展了广义线性模型的能力,使它们能使用关联的纵向数据和聚类数据。
二、非线性模型
能够将较为复杂的模型应用于数据。
• 多项式逻辑回归 (MLR) 可预测具有两个以上类别的分类结果。
• 二元逻辑回归可将数据分为两个组。
• 非线性回归 (NLR) 和受限非线性回归 (CNLR) 可估算非线性模型的参数。
• 概率分析使用响应比例的分对数(Logit)转换或概率单位变换来计算模拟值。
三、地理空间
分析支持用户对位置和时间数据进行集成、探索和建模。
• Statistics Premium 中的地理空间分析技术可帮助揭示地理空间数据中隐藏的关系和趋势。
• 空间-时间预测 (STP) 技术可使线性模型适应 2D 和 3D 空间内位置随时间推移进行的度量,支持用户预测这些领域的长期变化趋势。
• 使用广义空间关联规则 (GSAR) 发现空间和非空间属性之间的关联,此规则使用历史数据(例如,事件发生位置、事件类型和事件发生时间)来描述发生的事件,例如犯罪或疾病爆发。
四、模拟功能
帮助分析人员自动模拟许多可能的结果(输入不确定时),同时改进风险分析和决策制定。
• 蒙特卡罗模拟方法可以帮助您在现有数据不充分的情况下,根据现有的数据和/或已知的参数创建模拟数据集。
• 可对非数值型变量(如“男”和“女”)进行模拟,无需将其记录为数值变量。
• 现有的预测模型和数据可用作模拟的起点,包括从 Automatic Linear Modeling (ALM) 和 IBM SPSS Modeler 导出的模型。
• 生成输入数据时,会自动确定并使用分类输入之间的关联。
• 使用一组不同的随机值,反复计算结果,生成可能结果值的分布,使用户能够选择最优值。
• SPSS Statistics 可被用于分析模拟结果,以直观的形式呈现结果以及为决策者推荐的行动。
五、定制表
使用户能够轻松理解其数据,并针对不同受众以不同风格快速汇总结果。
• 包含推论性统计信息时,针对人口统计组、客户群、时间段或其他分类变量比较平均值或比例。
• 该软件可创建汇总统计信息(从针对分类变量的简单计数到离差测定),并按照使用的任何汇总统计信息对类别进行排序。
• 它包括三种主要的测试:独立性卡方测试、列平均值比较(t 测试)和列比例比较(z 测试)。
• 交互式的表构建器提供拖放功能来创建数据透视表。
• 它排除了特定类别,能显示缺少值的单元格,并将小计添加到表中。
• 表可实时预览并在创建时进行修改。表可导出至 Microsoft Word、Excel、PowerPoint 或 HTML,以便在报表中使用。
六、数据准备
简化了分析过程的数据准备阶段。
• Statistics Premium 可识别可疑或无效的案例、变量和数据值。
• 该软件允许您查看缺失数据的模式并汇总变量分布。
• Optimal Binning 为那些为名义属性设计的算法找到最佳可能结果。
• 自动数据准备 (Automated Data Preparation,ADP) 工具通过一个高效的步骤即可检测和纠正质量错误,找到缺少值的原因。
• 建议和可视化帮助您确定要使用的数据。
七、数据有效性和缺失值检查
提升了获得有显著统计意义结果的几率。
• Statistics Premium 可使用六种诊断报表从多个角度检查数据,然后估算汇总统计信息并确定缺少值的原因。
• 该软件可快速诊断因缺少数据而带来的严重问题。
• 它使您能够用估算值替换缺失的值。
• 它显示每种缺失值的类型以及每个个例的所有极值的快照。
• 通过将缺失值替换为估算值以包含所有组(甚至包括响应力较低的组)来消除隐含的偏差。
八、分类数据和数字数据
可用于预测结果并以图形方式显示关系。
• 该软件可通过感知图、双重图和三重图来发现底层的关系。
• 它使用类似于传统回归、主成份组件和典范相关的程序来预测结果并显示关系 - 帮助您处理并理解名义数据(例如,薪资)和顺序数据(例如,教育程度)。
• Statistics Premium 使您能够以可视化方式解释数据集,并在大型的分数、计数、等级、排名或相似性表中了解行与列之间的关系。
• 该软件可处理数字数据中的非标准残留数据或者预测变量(例如,客户或产品属性)与结果变量(例如,购买/不购买)之间的非线性关系。
• 提供了多种适用于数字数据和归类数据的方法,包括 Ridge Regression、Lasso、Elastic Net、变量选择和模型选择。
九、决策树
可更方便地标识组、发现各个组之间的关系和预测未来事件。
• Statistics Premium 以可视化方式确定模型的流动方式,因此您可发现特定的子组和关系。
• 该软件直接在 IBM SPSS Statistics 中创建分类树,因此,您可以使用结果直接在数据内对案例进行分段和分组。
• 它包括四种确立的树形增长算法:
① CHAID - 快速、统计型的多向树算法,用于快速有效地探索数据,并针对所期望的结果构建分段和概要信息。
② 穷举式 CHAID - CHAID 的一种变体,用于检查每个预测项所有可能的分支。
③ 分类和回归树 (C&RT) - 完整的二叉树算法,可对数据进行分区,并生成准确的同构子集。
④ QUEST - 一种统计算法,可快速有效地选择不包含偏差的变量,并构建准确的二叉树。
• 选择或分类/预测规则使用 IBM SPSS Statistics 语法、SQL 语句或简单文本(通过语法)生成。
十、预测
功能帮助您更快地分析历史数据并预测趋势。
• Statistics Premium 确保组织决策者可以理解和使用您提供的信息。
• 它会自动确定最适合的 ARIMA 或指数平滑模型来分析您的历史数据。
• 时间因果关系建模 (TCM) 技术可帮助揭示大量时间序列中隐藏的因果关系,并确定每一个目标序列的最佳预测变量。
• 一次可对数以百计不同的时间序列进行建模,而不是每次只能对一个变量建模。
• 模型集中保存至一个文件,以便在数据发生变化时可更新预测,而无需重新设置参数或者重新估算模型。
• 可编写脚本以自动使用新数据来更新模型。
十一、结构方程式建模
工具使您能够以更准确的方式构建结构方程式模型,比使用直观的拖放功能设计的标准多变量统计模型更准确。
• Statistics Premium 测试假设情况,并确认观测变量与潜变量之间的关系 - 获得比回归分析更深入的洞察。
• 它使您能够构建更能切实反映复杂关系的模型,因为无论是观测变量(例如,来自调查的非实验性数据)还是潜变量(例如,满意度和忠诚度),都可用于预测任何其他数值变量。
• 该软件的可视框架用于比较、确认并完善模型。
• 多变量分析包含并扩展了标准方法 - 包括回归、因子分析、相关分析以及方差分析。
• 该产品包含三种数据归因方法:回归、随机回归和贝叶斯算法 (Bayesian)。
十二、引导程序
简化了对模型稳定性和可靠性的测试,使生成的结果更加准确可靠。
• Statistics Premium 通过对原始样本的替换项进行重新采样,对某个估算项的采样分布进行估算。
• 它会估算填充参数(例如,平均值、中值、比例、比值比、相关系数、回归系数等)的标准误差和置信度区间。
• 该软件使您可以创建数以千计的数据集备用版本,以便进行更准确的分析。
十三、高级采样评估和测试
通过将样本设计整合到调查分析中,生成从统计意义而言更为有效的推论。
• Statistics Premium 提供处理复杂样本设计(例如,分层、分群或多阶段采样)所需的专业规划工具和统计信息。
• 由于它将样本设计整合到了调查分析中,因此可帮助您获得更理想的结果。
• 用户可使用分析和预测算法(包括预测事件的时间),在复杂的样本设计中更准确地处理数字和分类结果。
• 向导简化了计划创建、数据分析和结果说明过程。
十四、直接市场营销和产品决策工具
可帮助市场营销人员更轻松地发现适合的客户,提升营销活动效果。
• Statistics Premium 通过为相似或截然不同的客户或联系人创建集群,对这些人进行细分。
• 该软件利用一些共有特征对客户或联系人建档,以提高市场营销产品和活动的针对性。
• 它可设计倾向性分数,以确定购买可能性最高的人群。
• 测试包性能与控制包性能不相上下。
• 对营销活动的响应通过邮政编码来标识。
• 将营销活动响应数据与 Salesforce.com 集成,以跟踪商机线索和报告销售成果。
十五、高端图表(High-end charts)
使用户可以在一系列平台和智能设备上方便地创建和共享吸引人的可视化效果,并与之进行交互。
• Statistics Premium 拥有数十个内置的可视化模版,帮助您就分析结果进行沟通。
• 通过“拖放”方式创建图表,无需编程技能。
• 可以定制样式表和图形模板,以便在整个企业范围内设置新的图形标准,或与您的品牌匹配。
• 图形可部署在使用 IBM SPSS Collaboration and Deployment Services、IBM SPSS Statistics 和 IBM SPSS Modeler 的运营系统中。
• 该软件支持各种数据源,包括以定界符分隔的 IBM SPSS Statistics 数据文件以及常见的数据库源(例如,DB2、SQL Server、Oracle 和 Sybase)。
登录页面
重新设计了登录页面,使用户能够快速轻松地找到所需的 SPSS Statistics 功能。
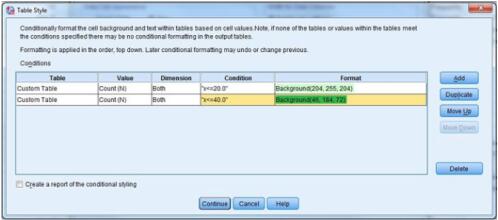
样式输出界面
根据单元格值,使用条件格式化,突出显示表中的单元格背景和文本。
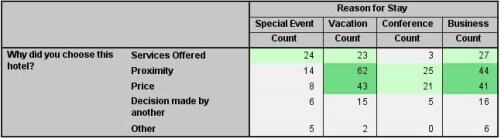
样式输出
将特定的属性(如颜色)应用于表单元格或行,引起用户对特定结果的注意。
Web 报告
通过智能手机和平板电脑(如 iPhone、iPad、iPod、Windows 和 Android 设备)中的 Web 浏览器,查看交互式 SPSS Statistics 报告。
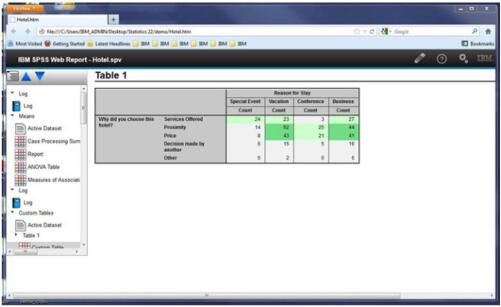
热图
蒙特卡罗模拟 (Monte Carlo simulation) 在显示目标和/或输入为分类状态的散点图时,帮助您自动生成热图。
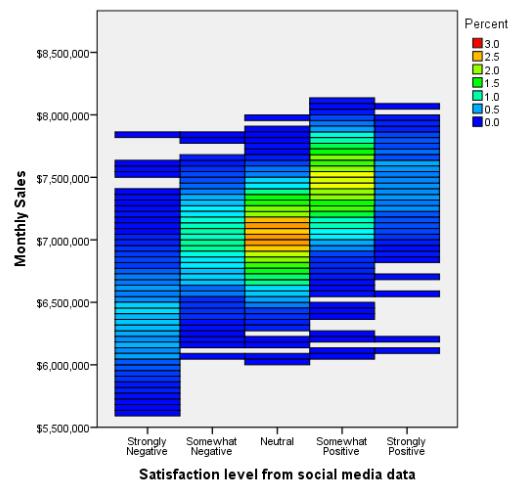
内核密度估算
在此图中,SPSS Statistics 显示了所选区域随时间变化的点密度(内核密度估算)。
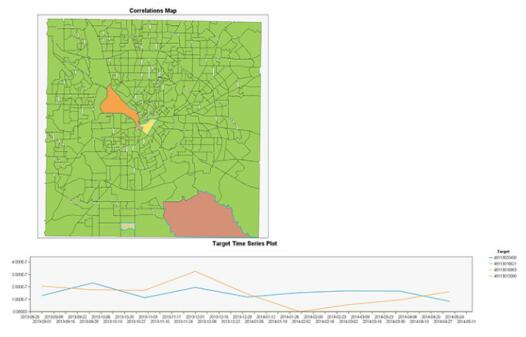
GSAR
正如此处所示,GSAR 可用于基于区域人口统计信息预测犯罪发生可能性最高的地点,如此图中所示。
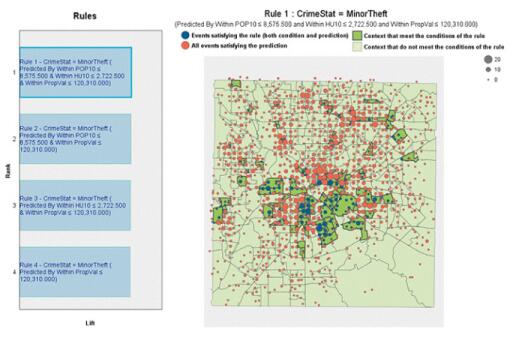
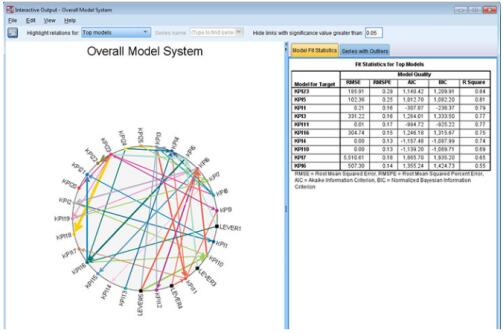
时间因果关系模型
此图显示了与时间因果关系模型系统中的前 10 个模型(最匹配的模型)关联的因果关系。监控关键绩效指标并跟踪各种可控指标(称为杠杆)数据的企业希望确定杠杆与 KPI 之间的因果关系,以便了解哪些杠杆影响哪些 KPI。该公司还希望了解在各 KPI 之间是否存在因果关系。
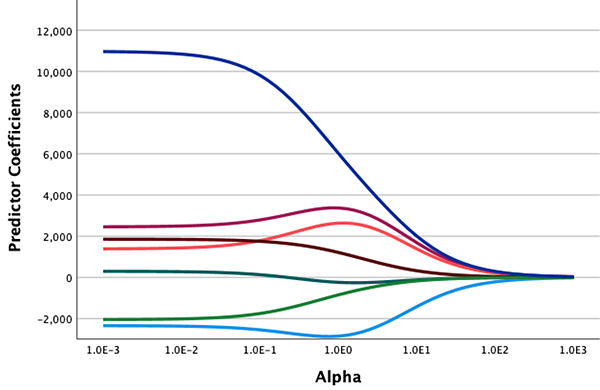
线性 OLS 替代方案
弹性网络
新的 "线性弹性网络" 扩展过程使用 Pythonsklearn.linear_model.ElasticNet用于估计一个或多个自变量上因变量的正规化线性回归模型的类。规则化组合了 L1 (套索) 和 L2 (岭) 惩罚。该扩展包含可选方式,用于显示给定 L1 比率的不同 alpha 值的跟踪图,以及基于交叉验证选择 L1 比率和 alpha 超参数值。当拟合单个模型或使用交叉验证来选择惩罚比率和/或 alpha 时,可使用保留数据分区来估算样本外性能。
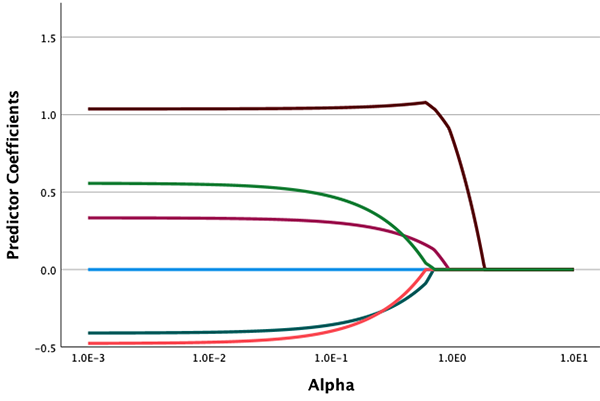
套索
新的线性套索扩展过程使用 Pythonsklearn.linear_model.Lasso用于估计一个或多个自变量的因变量的 L1 损失正规化线性回归模型的类,并包括用于显示跟踪图和基于交叉验证选择 alpha 超参数值的可选方式。当拟合单个模型或使用交叉验证来选择 alpha 时,可使用保留数据分区来估算样本外性能。
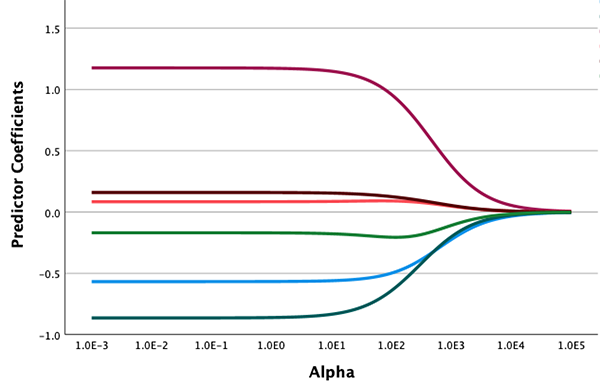
岭
新的线性岭扩展过程使用 Pythonsklearn.linear_model.Ridge用于估算一个或多个自变量上因变量的 L2 或平方损失正规化线性回归模型的类,并包括用于显示跟踪图和基于交叉验证选择 alpha 超参数值的可选模式。当拟合单个模型或使用交叉验证来选择 alpha 时,可使用保留数据分区来估算样本外性能。
参数加速故障时间 (AFT) 模型
新程序使用非循环生命时间数据来调用参数化生存模型过程。参数化生存模型假设生存时间遵循已知分布,此分析拟合加速失败时间模型,其模型效应与生存时间成正比。
参数生存模型 - SURV AFT
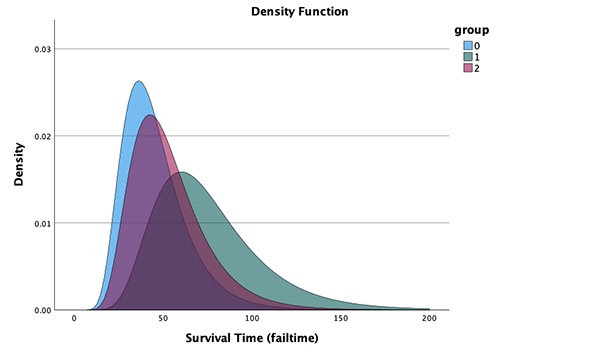
线性混合模型和广义线性混合模型中的 伪 -R2 测量
伪 -R2 度量和类内相关系数现在包含在线性混合模型和广义线性混合模型输出中 (如果适用)。确定系数 R2 是通常报告的统计量,因为它表示由线性模型解释的方差比例。类内相关系数 (ICC) 是一个相关统计,用于量化由多级/分层数据中的分组 (随机) 因子解释的方差比例。
命令语法
GENLINMIXED
输出现在包含 伪 -R2 度量和类内相关系数 (如果适用)。
LINEAR_ELASTIC_NET
新的扩展命令使用 Pythonsklearn.linear_model.ElasticNet用于估计一个或多个自变量上因变量的正规化线性回归模型的类。
LINEAR_LASSO
新的扩展命令使用 Pythonsklearn.linear_model.Lasso用于估算一个或多个自变量上因变量的 L1 损失正规化线性回归模型的类。该命令包含用于显示跟踪图和选择基于交叉验证的 alpha 超参数值的可选方式。
LINEAR_RIDGE
新的扩展命令使用 Pythonsklearn.linear_model.Ridge用于估计一个或多个自变量的因变量的 L2 或平方损失正规化线性回归模型的类。该命令包含用于显示跟踪图和选择基于交叉验证的 alpha 超参数值的可选方式。
MIXED
输出现在包含 伪 -R2 度量和类内相关系数 (如果适用)。
SURVREG AFT
新的扩展命令使用非循环生命周期数据调用参数生存模型过程。
Python 和 R 升级
Python 3.10.4 和 R 4.2.0 随 IBM SPSS Statistics 29一起安装。
选择个案 - 隐藏的个案
当选择了部分个案时,未选择的个案将不再隐藏在数据编辑器中,并且不会废弃未选择的个案。这表示返回到 统计信息 27.0.1 和更低版本的行为。
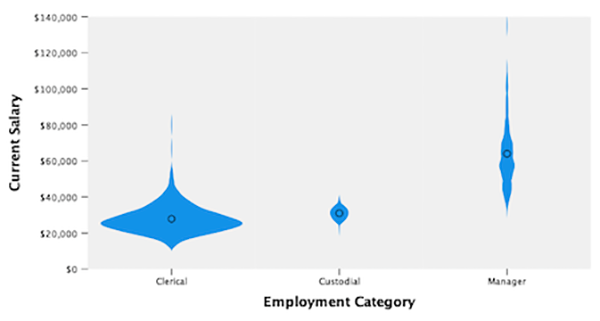
小提琴图
“图形板模板选择器”包括新的小提琴图,这是箱形图和内核密度图的混合体。小提琴图显示数据中的峰值,并用于可视化数字数据的分布。与只能显示汇总统计的箱图不同,小提琴图描述汇总统计和每个变量的密度。
工作簿方式增强功能
两个新的工作簿工具栏项: 显示/隐藏所有语法窗口 和 清除所有输出。
"状态栏" 上的新按钮,用于在经典 (输出和语法) 方式与工作簿方式之间进行切换。

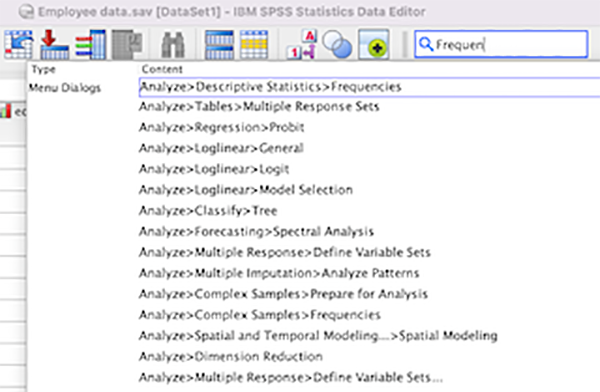
搜索增强功能
“搜索”功能提供了直接在工具栏字段中输入词汇以及在下拉窗格中查看结果的选项。
IBM SPSS Statistics for Windows
操作系统:Microsoft Windows 10(64位)*
处理器:2 GHz 或更快
显示:1024*768或更高
内存:需要 4 GB RAM,建议 8 GB RAM 或更多
磁盘空间:2 GB 或更多
IBM SPSS Statistics for Mac
操作系统:macOS High Sierra 10.13,macOS Mojave 10.14,macOS Catalina 10.15。
硬件:
内存: 4GB RAM 或更多 1024x768 显示
最小硬盘空间: 2GB
IBM SPSS Statistics for Linux
操作系统:SPSS Statistics只在以下平台上进行过测试和支持。Red Hat Enterprise Linux (RHEL) 8,Red Hat Enterprise Linux (RHEL) Client 7,Ubuntu 14.04 LTS,Ubuntu 16.04 LTS。
硬件:
内存: 4GB RAM 或更多 1024x768 显示
最小硬盘空间: 4GB
 北京友万信息科技有限公司,英文全称:Beijing Uone Info&Tech Co.,Ltd ( Uone-Tech )是中国大陆领先的教育和科学软件分销商,已在中国300多所高校建立了可靠的分销渠道。拥有最成功的教学资源和数据管理专家。如需申请软件采购及老版本更新升级请联系我们,咨询热线:010-56548231 ,咨询邮箱:info@uone-tech.cn 感谢您的支持与关注。
北京友万信息科技有限公司,英文全称:Beijing Uone Info&Tech Co.,Ltd ( Uone-Tech )是中国大陆领先的教育和科学软件分销商,已在中国300多所高校建立了可靠的分销渠道。拥有最成功的教学资源和数据管理专家。如需申请软件采购及老版本更新升级请联系我们,咨询热线:010-56548231 ,咨询邮箱:info@uone-tech.cn 感谢您的支持与关注。
地址:北京市昌平区中兴路21号院4号楼5层516 网站备案号:京ICP备16049373号-1]
联系方式:+86-10-56548231
