-

-
-

-
-

-
-

- 010-56548231
-

![]()

![]()

![]()

![]()
![]()

WordStat 是一款灵活且易于使用的文本分析软件——无论您是需要文本挖掘工具来快速提取主题和趋势,还是需要使用最先进的定量内容分析工具进行仔细和精确的测量。任何需要从大量文档中快速提取和分析信息的人都可以使用 WordStat。
我们的内容分析和文本挖掘软件可用于许多应用,例如开放式响应分析、商业智能、新闻报道的内容分析、欺诈检测等。WordStat 与SimStat、QDA Miner和Stata的无缝集成 – 来自 StataCorp 的综合统计软件,为您提供前所未有的灵活性来分析文本并将其内容与结构化信息相关联,包括数字和分类数据。
使用WordStat分析大量非结构化信息。该软件每分钟可处理2500万个单词,使用聚类,多维缩放,邻近图等功能快速提取主题并自动识别模式。
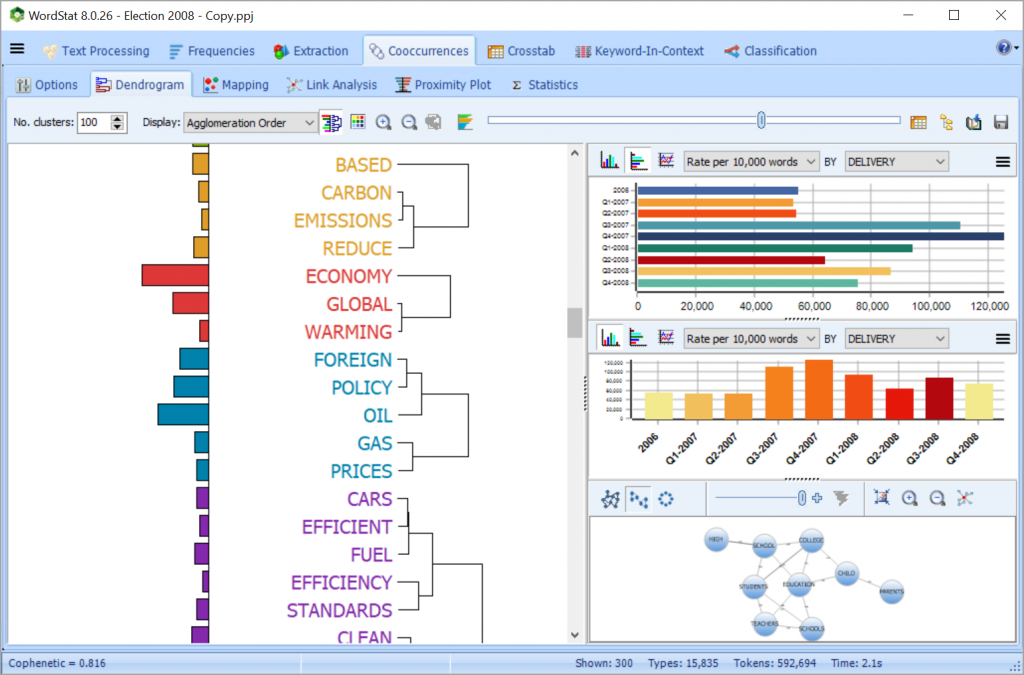
使用资源管理器模式快速轻松地从大量文本数据中提取含义,特别是针对那些文本挖掘经验很少的人。只需单击一下,就可以提取文档中最常用的单词,短语和最突出的主题。
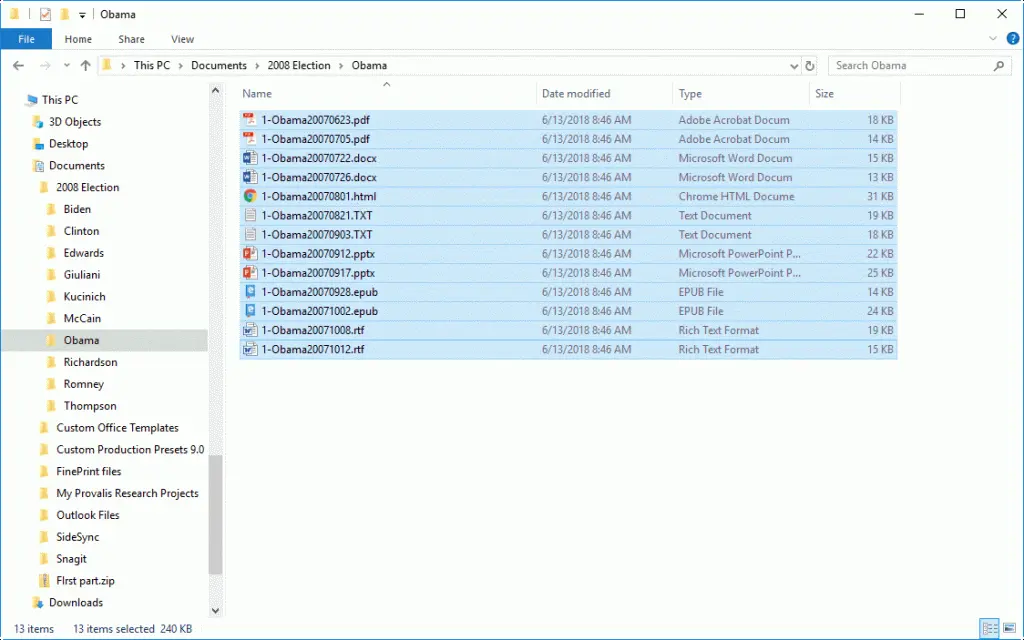
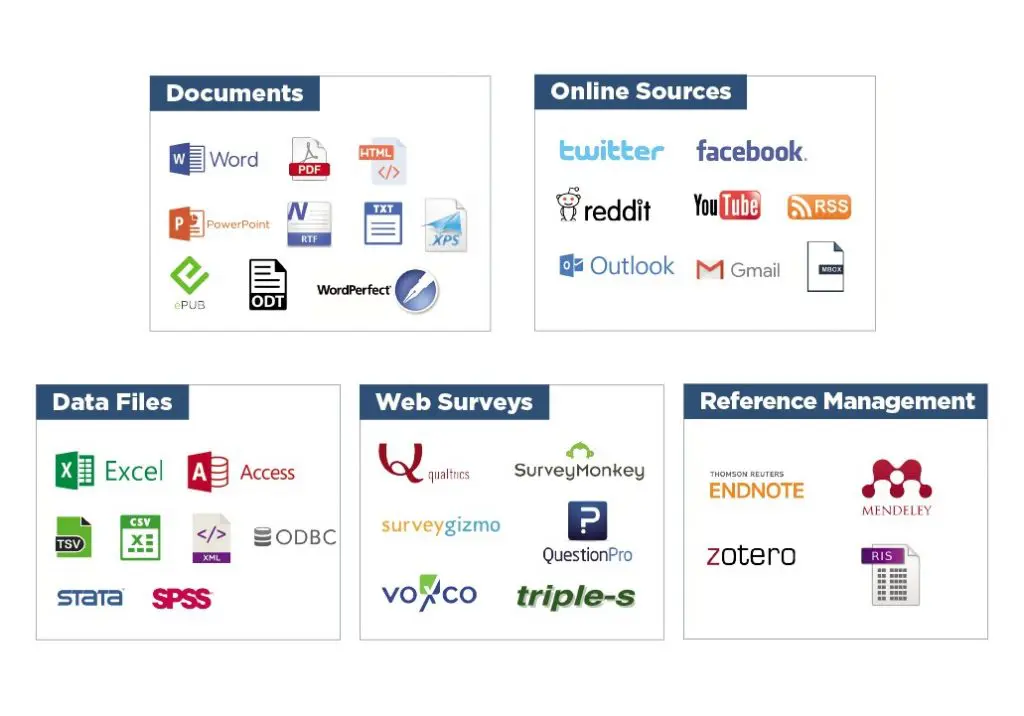
• 导入Word,Excel,HTML,XML,SPSS,Stata,NVivo,PDF和图像。连接并直接从社交媒体,电子邮件,网络调查平台和参考管理工具导入。
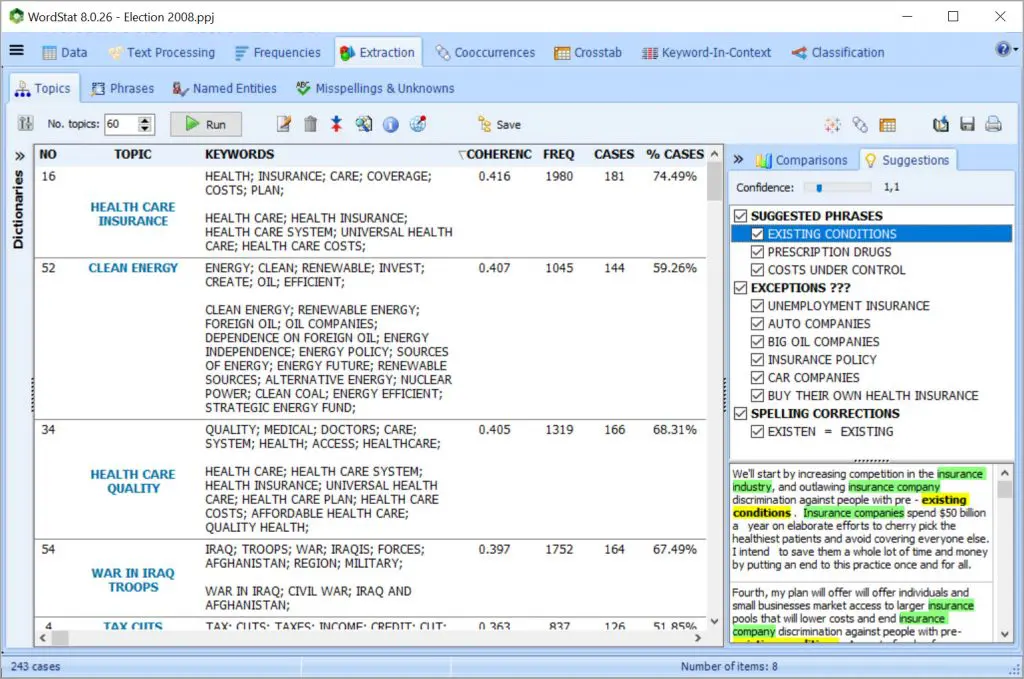
使用基于单词、短语和相关单词(包括拼写错误)的最先进的自动主题提取,从非常大的文本集合中快速了解最突出的主题。
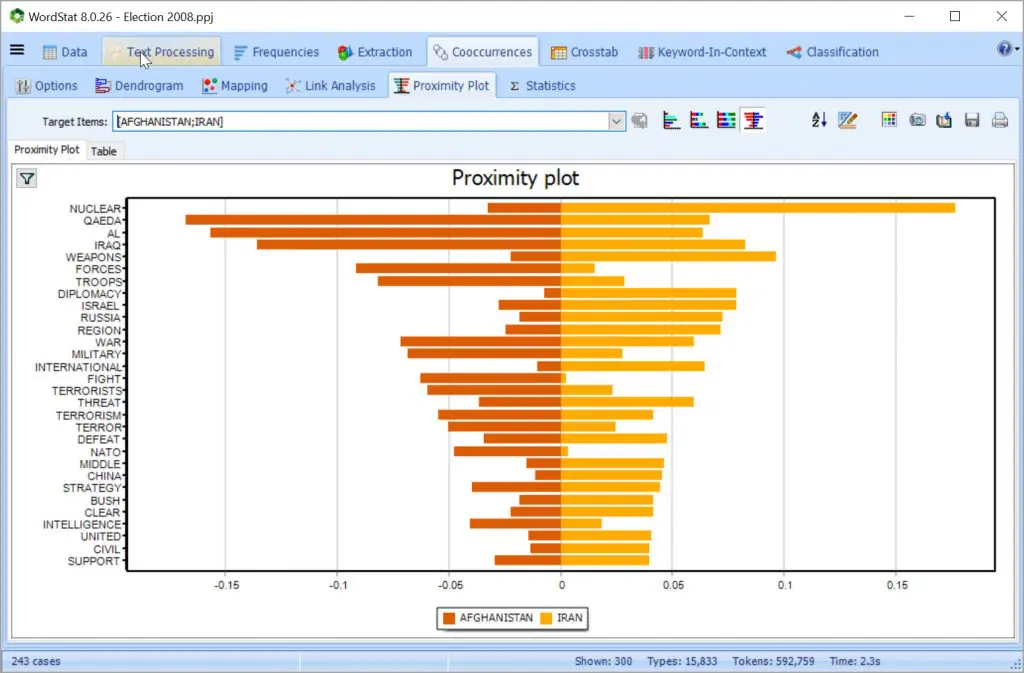
探索单词或概念之间的关系,并检索与特定连接关联的文本段。
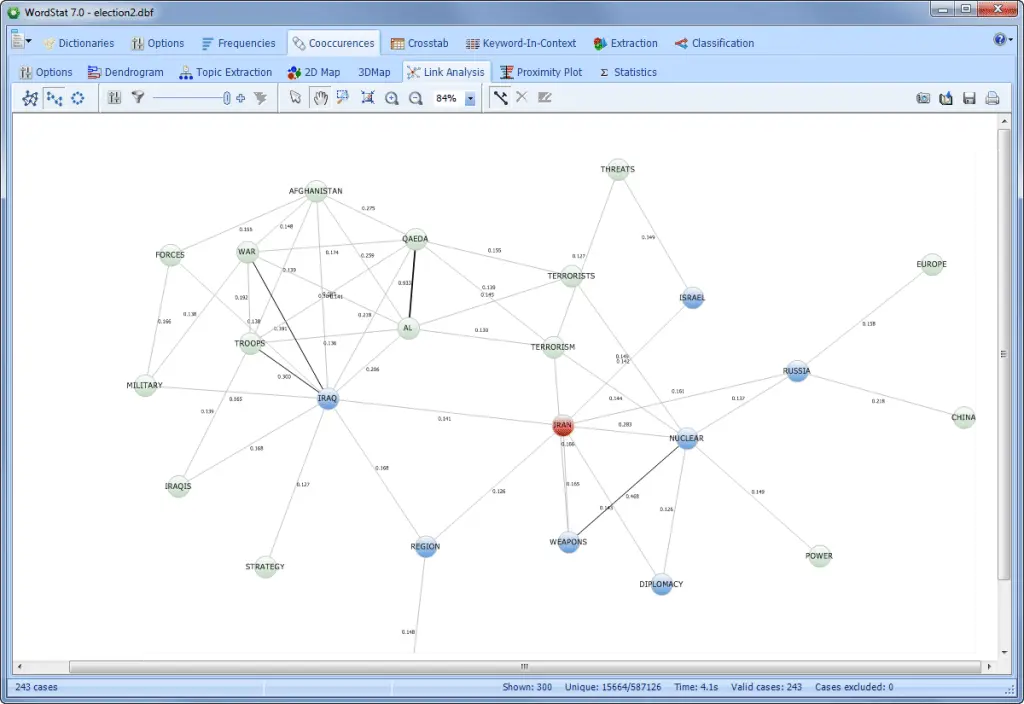
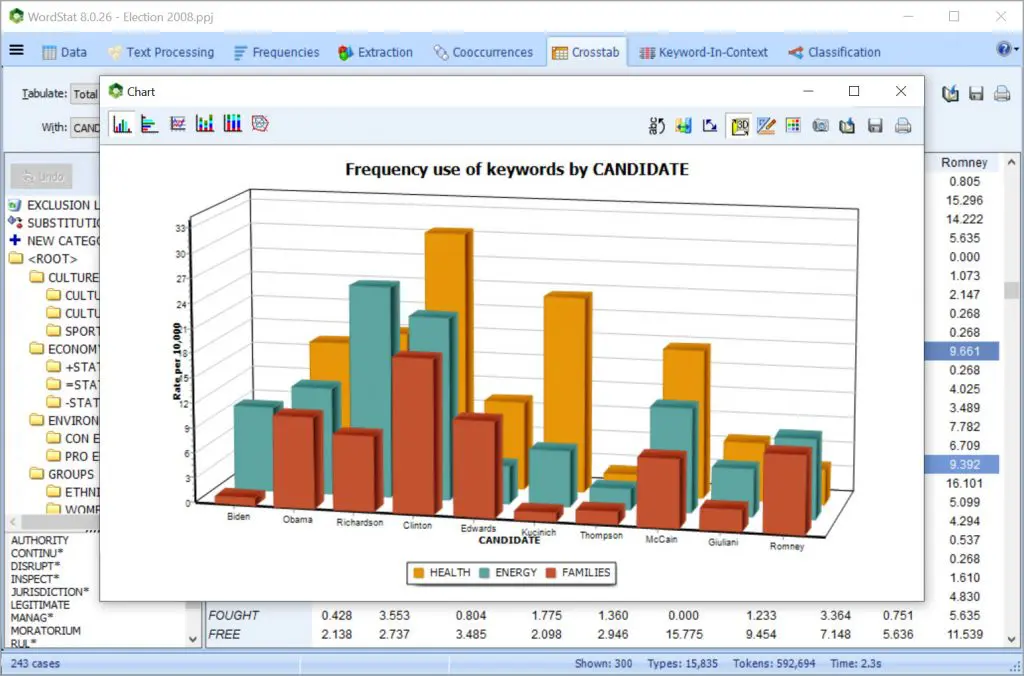
探索非结构化文本与结构化数据(例如日期,数字或分类数据)之间的关系,以识别子组之间的时间趋势或差异,或使用统计和图形工具(对应分析,热图,气泡图等)
使用现有词典实现全文分析自动化,或使用单词,短语,邻近规则等创建您自己的分类模型。
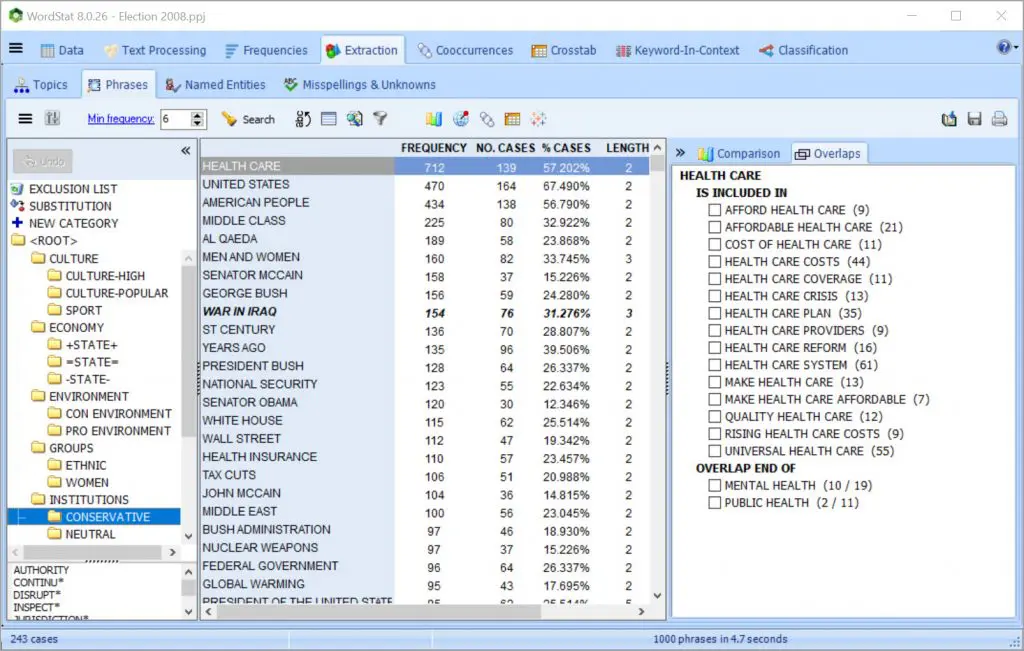
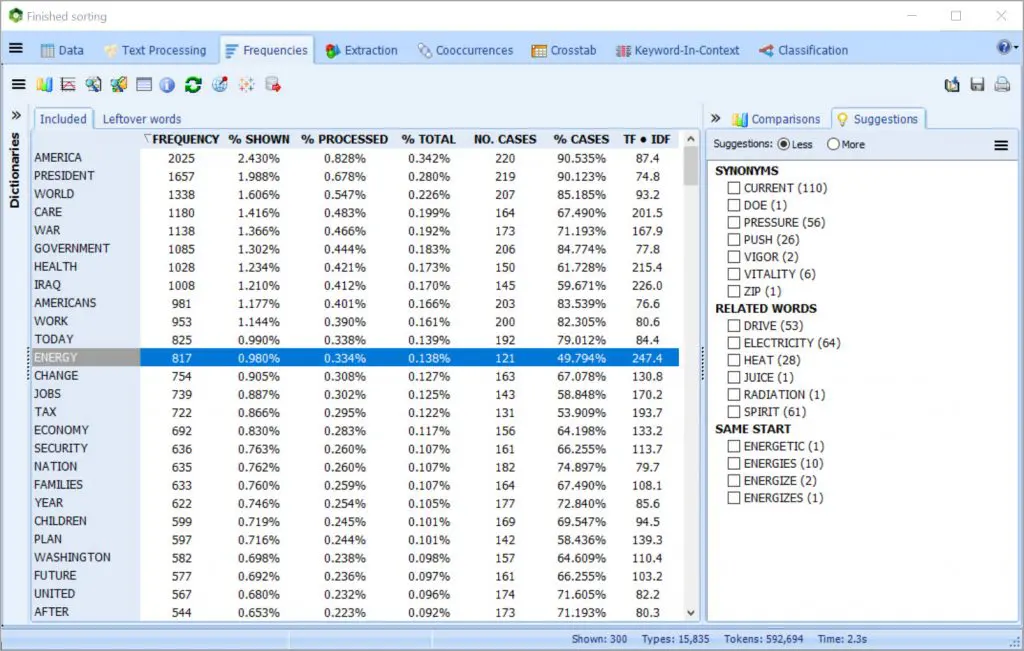
使用提取常用短语和技术术语并在文本集合中快速识别拼写错误,同义词,反义词和相关单词的工具,更快地构建词典
使用朴素贝叶斯和K最近邻来开发和优化自动文档分类模型。
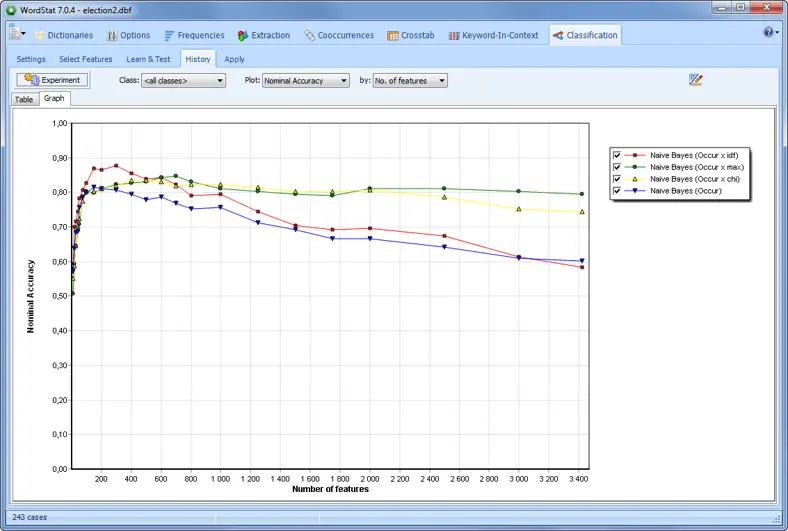
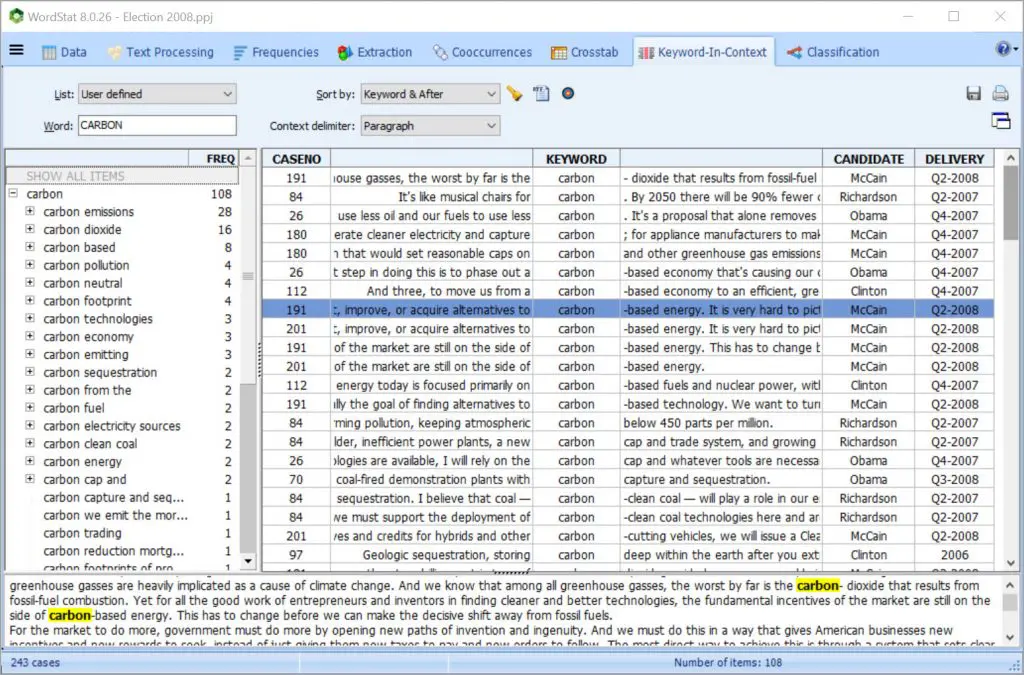
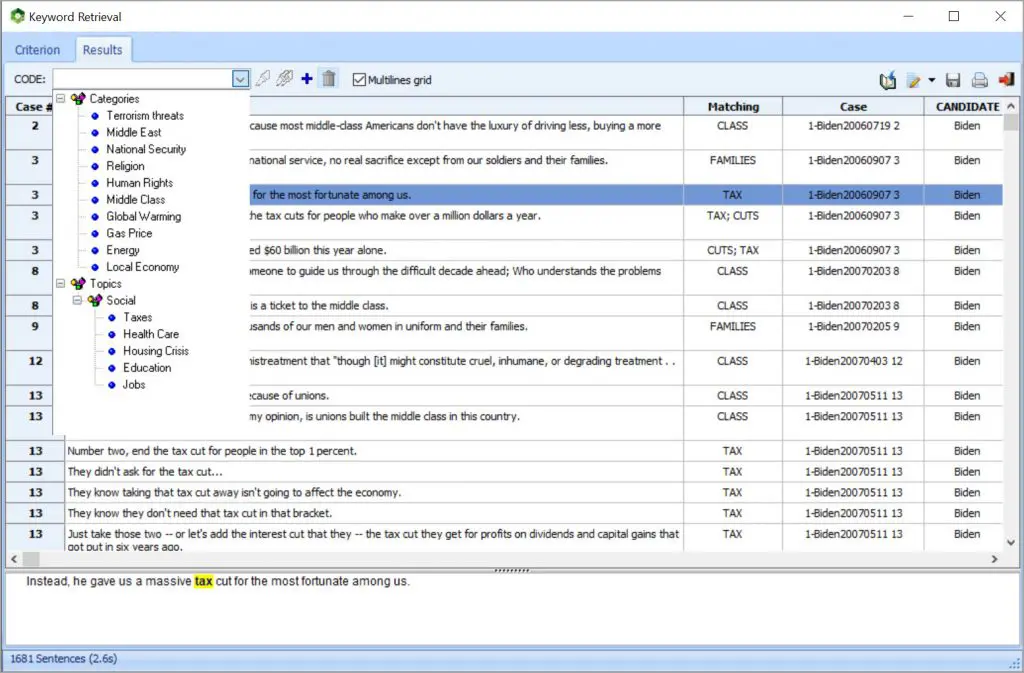
通过从几乎所有功能,图表或图形返回到文本来验证或深入分析。您可以使用“关键字检索”或“上下文中的关键字”功能来检索句子,段落或整个文档。这在建立分类法或消除词义歧义时特别有用。您还可以将QDA Miner代码附加到检索到的段。
将 WordStat与最新的定性编码工具(QDA Miner)结合使用,以在需要时更精确地浏览数据或对特定文档或提取的文本段进行更深入的分析。
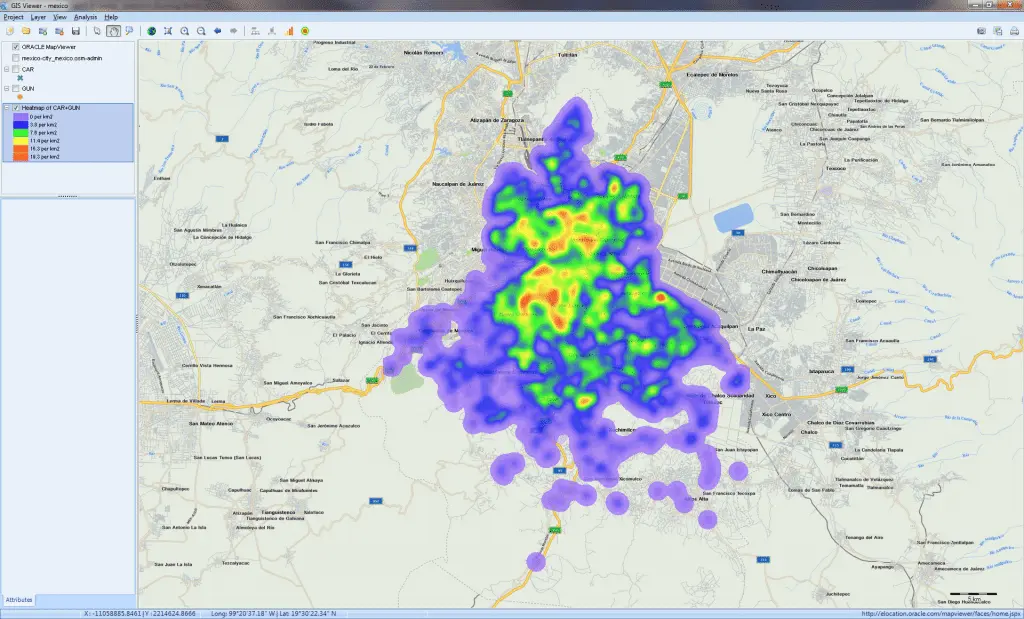
将非结构化文本数据与地理信息相关联,并创建数据点,主题地图和热图的交互式图表,以及用于将位置名称,邮政编码和IP地址转换为纬度和经度的地理编码Web服务。
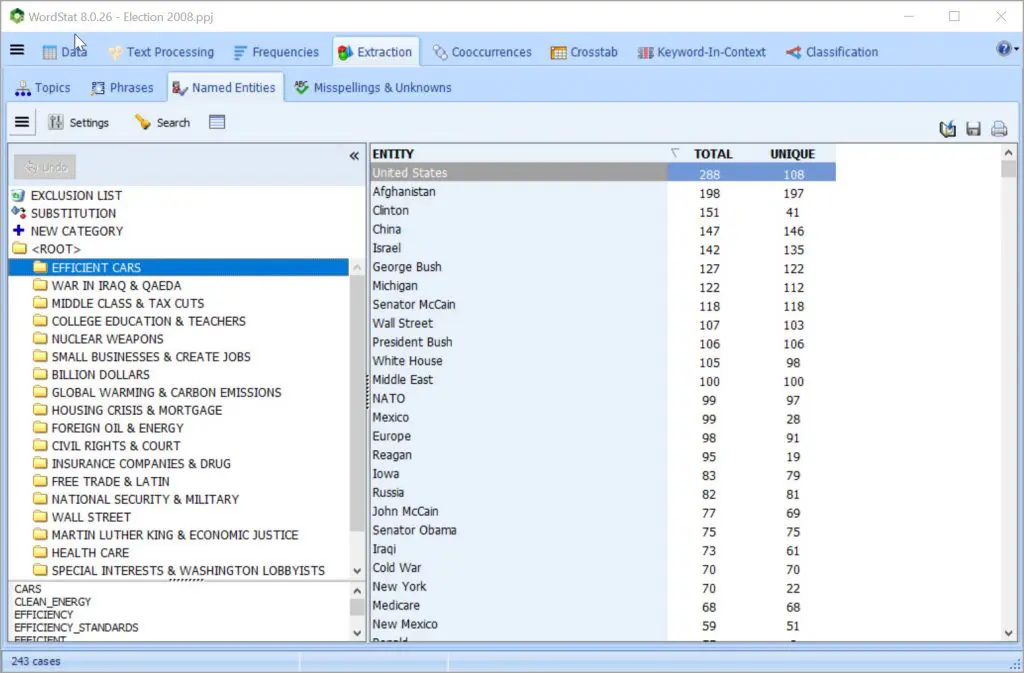
自动提取命名的实体,可以使用简单的拖放操作将其添加到分类字典中。
轻松将文本分析结果导出为常见的行业文件格式,例如Excel,SPSS,ASCII,HTML,XML,MS Word和图形(例如PNG,BMP和JPEG)
使用 Python 脚本及其全部开放源代码库预处理或转换文本文档,以便在 WordStat 中进行分析。

操作系统:Microsoft Windows XP , 2000 , Vista , Windows 8和10
内存:从256MB(XP)到1GB(Vista , Windows 8和10)
磁盘空间:40MB
 北京友万信息科技有限公司,英文全称:Beijing Uone Info&Tech Co.,Ltd ( Uone-Tech )是中国大陆领先的教育和科学软件分销商,已在中国300多所高校建立了可靠的分销渠道。拥有最成功的教学资源和数据管理专家。如需申请软件采购及老版本更新升级请联系我们,咨询热线:010-56548231 ,咨询邮箱:info@uone-tech.cn 感谢您的支持与关注。
北京友万信息科技有限公司,英文全称:Beijing Uone Info&Tech Co.,Ltd ( Uone-Tech )是中国大陆领先的教育和科学软件分销商,已在中国300多所高校建立了可靠的分销渠道。拥有最成功的教学资源和数据管理专家。如需申请软件采购及老版本更新升级请联系我们,咨询热线:010-56548231 ,咨询邮箱:info@uone-tech.cn 感谢您的支持与关注。
地址:北京市昌平区中兴路21号院4号楼5层516 网站备案号:京ICP备16049373号-1]
联系方式:+86-10-56548231
